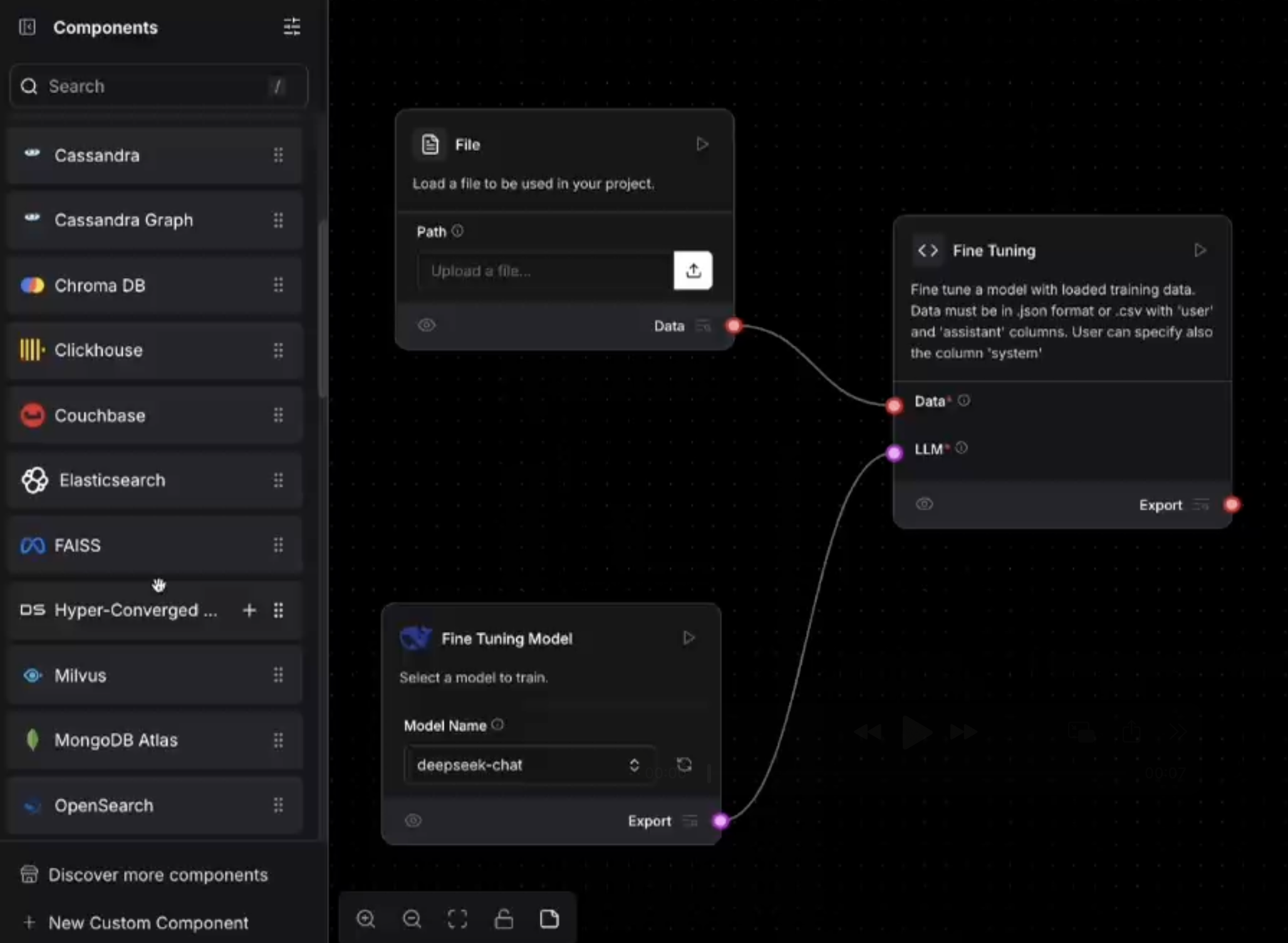

Select the open-source language model you want to fine-tune, such as LLaMA or Mistral. This choice determines the model’s foundational capabilities and influences the results of fine-tuning.are looking for.

Bring in your training dataset from your local files or directly import from Hugging Face repositories. Ensure your data is relevant and aligned with your target task for optimal results.preliminary evaluation of their resumes, experience, and core skills.

Use Priene AI’s preprocessing pipeline to automatically clean, format, and chunk your unstructured data. This ensures consistency and compatibility with your selected model’s input requirements.

Define the fine-tuning setup, including model-specific parameters, training epochs, and evaluation metrics. With over 30 parameters, Priene offers full control without needing to write code.

Choose between high-performance GPU options like Nvidia H100 or L40 based on your training speed and budget. Priene allocates and configures the environment automatically.

Set your export preferences, including output format and deployment-ready integrations. Once complete, your fine-tuned model is ready to use across inference tools or agent workflows.
Priene is designed to make fine-tuning accessible to everyone, regardless of technical background. With a fully visual interface, you can upload your data, configure training parameters, and launch the fine-tuning process in just a few clicks. No coding required—whether you're building a chatbot, document summarizer, or a domain-specific model. For advanced users, over 30 parameters are available for deep customization, while beginners can rely on smart defaults and step-by-step guidance to get started quickly and effectively.